For those who are more keen towards going in guns blazing, here is the repo link.
Now, onto the verbage.
My first (tiny) step towards making academic publishing better is actually developing a good understanding for the tools I want to use. So, I made my own hacked-together clone of ConnectedPapers, which takes a preprint from arXiv and recommends similar preprints to help researchers expedite literature review. The point of this blog post is namely to showcase that once you have a slightly-above-beginner-level grasp of the Python ecosystem, slapping together a data-driven service that solves a problem can be well within the scope of something a junior developer works on over the course of multiple weekends.
In some near future, I’ll find the time to put together a tool which basically allows you to upload a collection of citations, and then puts together a journal based on the topics extracted from the papers. But for now let’s focus on the basics: a recommendation engine for research papers.
Architecture Overview
It’s really amazing how easy it is to play Mr. Potato Head
with Python libraries until you get just enough functionality to make
something really cool. All in all, cloc tells
me I’ve only written about 407 lines of code. Of course, that ignores the
thousands of lines of dependencies I rely on. My point is that after a handful
of blog posts, a couple hours of reading documentation and watching YouTube
tutorials, I was able to cobble together a working version of this service in
about 7 weekends. Anyways, here’s a simple diagram showing how all the parts
of the backend talk come together to provide recommendations:
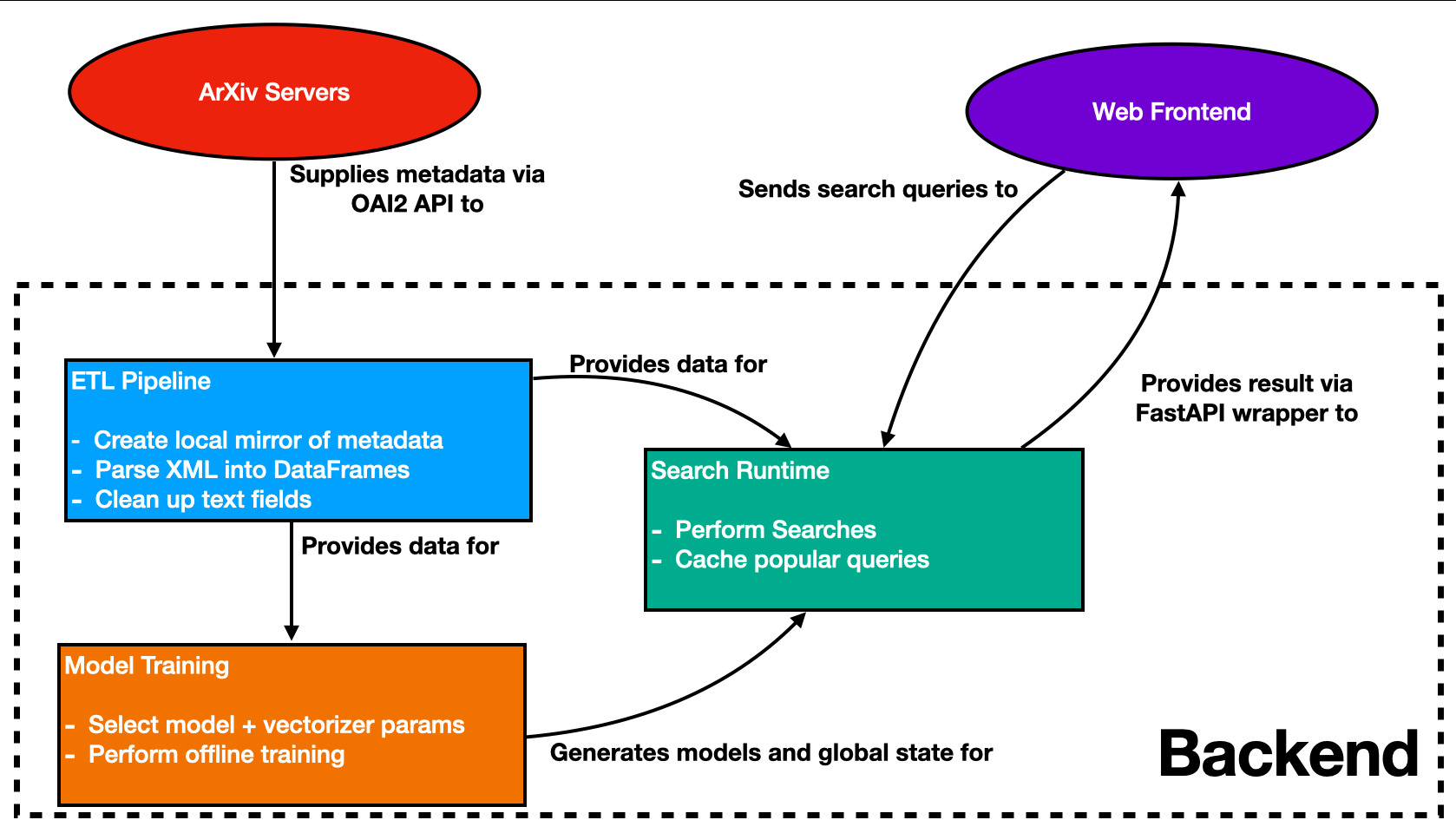
Indexr Backend
ETL: OAI2, and Parquet files
First things first, we need data. The purpose of this subsystem (located in
the etl/ folder) is to accumulate all the metadata of all the arXiv preprints
into a datastore which I can use throughout the rest of my code. Thankfully,
arXiv offers all of their paper metadata in bulk via an OAI2 API
endpoint which is documented
here. This was attractive to me for the
following reasons:
-
arXiv had yet to release their data pipeline on Kaggle.
-
There was a pre-existing harvester tool which worked for arXiv and any other database that exposed an OAI2 API. The tool is called metha, and the repo is here. It’s a great piece of software, props to the creator(s) and contributors.
-
Working with the full LaTeX sources requires terabytes of storage that I didn’t have at the time.
-
I could build a large (>1.7e6 rows) copy of the metadata, and not flood arXiv’s main API with traffic. A large dataset means that I have more than enough for an offline model of the preprints, and I won’t upset the admins (too much, anyways). I can also subset this dataset for exploratory analysis and testing without any network traffic once I have a local copy.
At a high level, here’s a step-by-step process required to produce the dataset I use for training models and providing search results at runtime:
-
Run metha, collecting all the metadata for all papers in their default Dublin Core format. Since metha caches results, it’s easy to stay-up-to-date without generating loads of traffic.
-
Decompress the XML files, clean up the metadata a little bit, and then save the data in Parquet format. This all happens in
oai_dc_metadata.py. -
Accumulate the parquet files into a a giant pandas DataFrame in memory, and then generate categorical encodings for the tags used on each paper. This encoding is similar to a one-hot encoding, but instead of just having one bit set, it has N bits set, where N equals the number of tags for the paper. After the encodings are added the DataFrame, I save the “master” dataframe, and then I save a subset of the past five years’ worth of papers to a separate file as the dataset which I actually intend to offer in production. This all happens in
gather_parquets.py
Since steps 2 and 3 form a neat map-reduce pattern, I’ve split them up into two files, the first which I can run in parallel using GNU parallel. To make deployment easier, I’ve cooked up a Docker container which does all of this by setting up a minimal environment and launching this bash script.
Where’s the Exploratory Data Analysis?
Before I go into the model training subsystem, I should clarify something. When I started this project, I had prior exposure to topic modeling due to prior exposure in an NLP class I took during my undergrad. Because I was so confident in the microscopic amount of knowledge I had on the topic, I went straight straight into building a model without doing any exploratory data analysis (EDA). In retrospect, this was a bad choice. Always do some EDA! A big reason why EDA is important is because it helps you uncover the unknown unknowns for not just your dataset, but also both your training pipeline and your inference pipeline. Here are some of the problems I still have yet to address, which effectively require me to do (better) EDA:
-
I have no clean way of visualizing semantic similarity betwen documents, or any other form of similarity for that manner. I am in the process of building a 2-D projection of my corpus using UMAP.
-
My training suffers from some significant imbalance in latent topics which has gone unaccounted for in the training process (for now). There are ways around this, but proper EDA would make subsetting my data in a “semantically fair” manner much easier.
I justified skipping the work visualizing the dataset because I really wanted to get some end results quickly. While this is hopefully the first in a series of works I will do on automating the curation of scientific research, I was really craving the sense of having “made” something. I still think this wasn’t a bad rationale, but I probably would’ve also found some cool visualizations of my data to be both rewarding and cool additions to the blog post.
Model Training: Scikit + Gensim
The original draft of my training code was lifted from the Scikit-learn example on topic extraction, which you can see here. I had some prior experience with Latent Dirichlet Allocation in an academic setting, and my prior exposure to scikit-learn pushed me towards their API. Unfortunately, their LDA implementation is quite the memory hog and not the easiest to configure, so I’ve instead decided to set up LDA with GenSim. However, I’ve run into some hiccups there as well. I think I’ve just been a bit dense with the setup and I’ve forgotten to configure something obvious, but their example for logging model perplexity at training time isn’t working on my machine.
As a result of these shenanigans, I’m currently using NMF in the production build of my backend because it trains fast, doesn’t have a huge memory footprint, and mostly “Just Works”, even if the recommendations aren’t as nice as I’d like them to be.
Enough with the rambling, here’s a high level walkthrough of the training script as it works in production:
- Load the training data from the parquet file.
- Run the paper abstracts through a TfidfVectorizer, generating a doc-term matrix. Every row is a document, and every column is a term token in the vocabulary of our corpus. A row-column entry contains the TF-IDF score of that word in that document.
- Spin up an instance of the NMF class and then do a
doc_topic_matrix = nmf_model.fit_transform(doc_term_matrix), thus creating our document-topic matrix. - Save all the matrices and the vectorizer to disk for reuse in the search runtime.
I’m keeping most of this discussion pretty high level, since there are already a fair amount of resources out there covering the concepts in detail. I quite like this, in particular section 6.2. It’s free and quite comprehensive. Furthermore, you really only need a surface-level understanding of these concepts to get this done, which is part of the magic of these libraries. If you have the ability to use your own eyes and brain to process natural language, then you too can read scikit-learn documentation to build your own basic NLP tools/services. Some patience and Python experience required.
Search Runtime: Putting the model and data together
Now that we have a model and data, we can start building search functionality
exposed via REST API using FastAPI. For
cleanliness reasons, I have all computation and data structures handled in the
search_runtime.py and then the FastAPI wrapper is in its own backend.py
module. This makes it easy to reuse the code/data I’ve done for the search
runtime in testing/visualization scripts, which are now rapidly multiplying
inside my indexr folder.
The search runtime module is decently commented, but I’d like to bring your attention to two key functions:
-
topic_search(query_id: str, top_n: int = 10)is the main function where I do the recommendations. The LRU cache decorator helps shave off about 10-15% of query time in my load tests, assuming that 80% of the queries are for the top 20% most popular papers. -
keyword_search(query: str, top_n: int = 10)is an alternative endpoint intended to be used as a fallback for queries that don’t fit the regex for arXiv paper IDs on the frontend.
Both of these functions use cosine similarity for comparing vectors. This project opted for jaccard distance instead, and it makes more sense, but I’ve gotten the cosine distance code quite optimized, and the results aren’t terrible so I’m keeping it for now, until I come up with a way of doing fast, efficient Jaccard similarity for sparse matrices and dense vectors that doesn’t stick out like a sore thumb in my codebase.
What next?
So this is really just a rough draft for automating one of the first parts of academic publishing system: content curation. There are a couple semi-obvious ways I can improve upon what I have so far:
-
More repositories: The magic of the metha harvester is that for the most part, adding more papers means just pointing metha at a new URL and some new parsing code.
-
Better hyperparameters: The NMF recommender is a little subpar because I haven’t dealt with class imbalance across preprint tags and I haven’t done much in terms of hyperparameter search.
-
A better algorithm: I’ve got an idea for how to train a recommender model that combines the strengths of autoregressive language models with prior work on clustering citation graphs, but I’d need to start building said citation graph, which is easier said than done.